Run production LLMs for $0.01 per job
We analyzed 200 GitHub issues with a 14B model on two $400 GPUs. Total cost: one cent. LLMKube makes self-hosted inference actually work on hardware you can afford.
20x cheaper than cloud GPUs • Works on consumer hardware • Kubernetes-native
See it in action
Deploy GPU-accelerated LLMs in seconds with the llmkube CLI
Why LLMKube?
Local LLMs are great for prototyping. Scaling them for a team is where it gets hard.
The Scaling Challenge
- ✗ Silent failures with no alerts
- ✗ Multi-GPU memory math by trial and error
- ✗ Updates that break your setup
- ✗ Docker Compose that doesn't scale
- ✗ One person managing everything
- ✗ Every machine set up by hand
With LLMKube
- ✓ Health checks that actually tell you when things break
- ✓ Automatic GPU memory management
- ✓ Helm-pinned versions that don't break on update
- ✓ Infrastructure as code, not scripts and duct tape
- ✓ Your whole team can deploy and manage
- ✓ Prometheus alerts before users notice
Ollama for dev. vLLM for speed. LLMKube for production.
The platform layer your inference engine is missing
How it works
The init container pattern: Separate model management from serving
LLMKube Architecture
Click on any component to learn more about it
💡 Innovation: Init Container Pattern
LLMKube uses Kubernetes init containers to separate model downloading from serving. This means:
- Fast cold starts: Models are cached in persistent storage
- Separation of concerns: Download logic separate from inference logic
- Kubernetes-native: Uses standard patterns that platform engineers already know
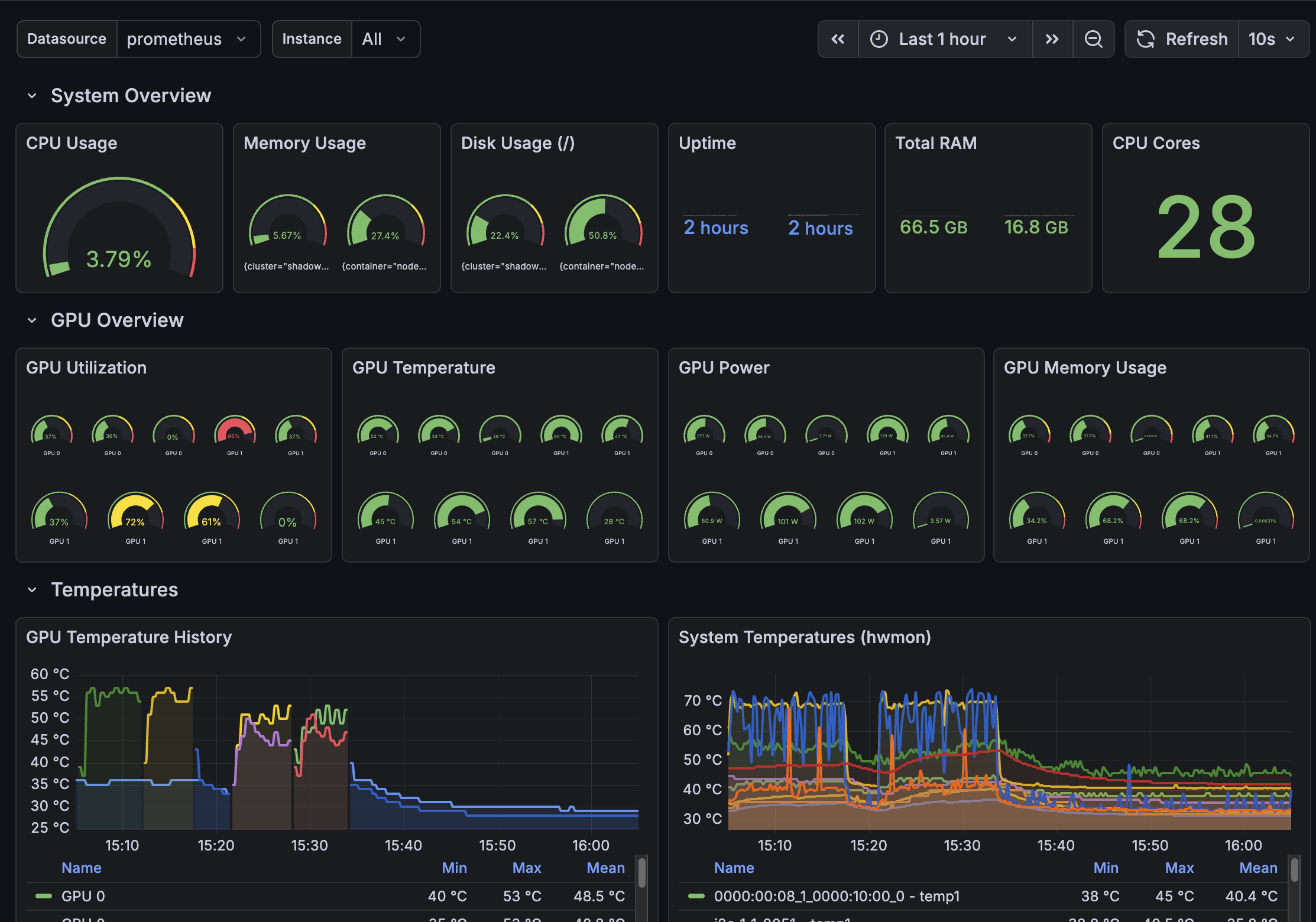
Production-validated performance
Real benchmarks from GKE deployments - CPU and GPU
CPU Baseline
Cost-EffectiveConfiguration
- Model:
- TinyLlama 1.1B Q4_K_M
- Platform:
- GKE n2-standard-2
- Model Size:
- 637.8 MiB
Performance
- Token Generation:
- ~18.5 tok/s
- Prompt Processing:
- ~29 tok/s
- Response Time:
- ~1.5s (P50)
- Cold Start:
- ~5s
GPU Accelerated
17x FasterConfiguration
- Model:
- Llama 3.2 3B Q8_0
- Platform:
- GKE + NVIDIA L4 GPU
- Model Size:
- 3.2 GiB
- GPU Layers:
- 29/29 (100%)
Performance
- Token Generation:
- ~64 tok/s
- Prompt Processing:
- ~1,026 tok/s
- Response Time:
- ~0.6s
- GPU Memory:
- 4.2 GB VRAM
- Power Usage:
- ~35W
- Temperature:
- 56-58°C
Production Ready: GPU acceleration delivers 17x faster inference with full observability (Prometheus + Grafana + DCGM metrics). Both CPU and GPU deployments are production-ready with comprehensive monitoring and SLO alerts.
Production-grade LLM orchestration
Everything you need to run local AI workloads at scale, with the operational rigor of modern microservices
Reproducible Deployments
Helm chart with pinned versions. No more "update broke my setup." Deploy the same config across dev, staging, and prod.
Local Testing with Metal
Test GPU-accelerated inference locally on Apple Silicon Macs with Metal support. Run on Minikube in under 10 minutes.
GPU Acceleration
Production-ready GPU inference with NVIDIA CUDA support. Achieve 17x faster inference with automatic GPU layer offloading.
GPU Queue Visibility
See exactly where your workloads stand. Queue position and GPU contention visible in kubectl status. Priority classes control scheduling.
CLI Benchmarks
Validate deployments before production. Five test suites, automated sweeps, and markdown reports you can share with your team.
Grafana Dashboard
Pre-built GPU observability dashboard. Track utilization, temperature, memory, and inference latency across your cluster.
Multi-GPU Without the Math
Stop guessing at VRAM. Deploy 70B+ models across GPUs with automatic layer sharding. No trial-and-error memory tuning.
Kubernetes Native
Deploy LLMs using familiar kubectl commands and YAML manifests. Integrates seamlessly with your existing K8s infrastructure and GitOps workflows.
Air-Gap Ready
Run LLMs in completely disconnected environments. Perfect for defense, healthcare, and regulated industries that can't use cloud APIs.
Know When Models Die
No more silent failures. Prometheus alerts, Grafana dashboards, and DCGM GPU metrics tell you something's wrong before users notice.
Edge Optimized
Distribute inference across edge nodes with intelligent scheduling. Model sharding for efficient resource utilization.
SLO Enforcement
Define and enforce latency targets, quality thresholds, and performance SLAs. Self-healing controllers keep your services running.
OpenAI Compatible
Drop-in replacement for OpenAI API endpoints. Use existing tools and libraries without code changes.
Deploy an LLM in seconds
Simple, declarative YAML that feels native to Kubernetes developers
apiVersion: inference.llmkube.dev/v1alpha1
kind: Model
metadata:
name: phi-3-mini
spec:
source: https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-q4.gguf
format: gguf
quantization: Q4_K_M
hardware:
accelerator: cuda
gpu:
enabled: true
count: 1
resources:
cpu: "2"
memory: "4Gi"Built for real-world deployments
From air-gapped data centers to distributed edge networks
Defense & Government
Deploy classified AI assistants in SCIF environments with TEE support and attestation. Meet CMMC and FedRAMP requirements.
- Air-gapped deployment
- Complete audit logs
- Zero external dependencies
Healthcare & Life Sciences
Run HIPAA-compliant AI assistants for clinical decision support without sending PHI to external APIs.
- HIPAA compliant
- PII detection with eBPF
- On-premises deployment
Manufacturing & Industrial
Deploy AI assistants on factory floors with poor connectivity. Distributed inference across edge devices.
- Offline-first operation
- Low-latency edge inference
- Resource-constrained optimization
Financial Services
Run AI models in regulated environments with complete data sovereignty and compliance guarantees.
- Data sovereignty
- Compliance-ready logging
- High availability SLAs
Early Adopter Program
Help shape the future of LLMKube and get direct access to the maintainer.
What You Get
- Private Discord with other early adopters
- Direct input on the roadmap
- Your logo on our website (when ready)
- Early access to new features
What We Need
- Real-world feedback on your use case
- 30 minutes monthly for a feedback call
- Permission to share your story (anonymized if needed)
Apply to Join
Ready to deploy your first LLM?
Join the growing community of developers and enterprises running production AI workloads on LLMKube
Open source and free forever • Enterprise support coming soon