Production-Ready LLM Infrastructure
vLLM, TGI, llama.cpp, or bring your own — one operator for every runtime.
How it works
The init container pattern: separate model management from serving
Two lanes: control plane above, data plane below. The Model Controller downloads weights once per namespace into a shared cache. The InferenceService Controller creates pods whose init container mounts that cache before the runtime starts. Cold-starting a new replica is a pod boot — no re-download.
Hover or focus a component for detail
Init Container Pattern
Models cached in persistent storage
Download logic separate from inference
Standard patterns engineers already know
What's working today
Production-validated features ready for your deployments
Foreman: Agentic Coding on Your Fleet
v0.9.0A Kubernetes-native control plane for coder, verifier, and reviewer agents running on your own hardware. Dispatch a GitHub issue and Foreman schedules the work across your FleetNodes, gates the diff, reviews it against a rubric, and opens the pull request.
- Capability-aware scheduling across heterogeneous FleetNodes, with orphaned-node reaping
- Coder agents in-process or as Kubernetes Jobs, with escalation to a larger model on failure
- Deterministic gate jobs plus rubric-driven LLM review before any PR opens
llmkube foreman dispatchfans issues across coder agents- 41 pull requests opened by local models on this project's own repo
AMD GPUs via Vulkan
v0.8.8First-class AMD acceleration on the Vulkan/RADV backend. Set vendor: amd and runtime: vulkan on the model's GPU spec, and the operator schedules LLMKube's own hardware-gated llama.cpp Vulkan image onto your AMD node, with no ROCm install required.
- Strix Halo (Radeon 8060S, gfx1151) with 128GB unified memory
- Scheduled on
/dev/drivia a device plugin, nonvidia.com/gpu - Own-built image, hardware-smoke-gated on real gfx1151 before release
- ROCm runtime tier is a planned follow-on
ModelRouter Phase 1
v0.7.8One OpenAI-compatible endpoint that routes across local InferenceServices and external providers (Anthropic, OpenAI, LiteLLM, Bedrock, Vertex). Declarative rules match on data classification, capability, task complexity, or headers. Fail-closed for regulated data; agent code shrinks to "talk to this URL."
- Fail-closed apply-time validator blocks PII rules pointing at cloud
- Per-rule / per-backend / global timeouts (TTFT)
- Half-open circuit breaker with cloud-tier connection lifecycle
- Streaming SSE passthrough, no buffering, 32 MiB request cap
- Structured audit log per request (rule, backend, latency, outcome)
Self-Updating Agent Fleet
v0.8.6Declarative, health-gated updates for off-cluster agents (Apple Silicon Metal and edge), the way Helm and brew handle the rest of the stack. Publish an AgentRelease, approve it, and the operator rolls the fleet one node at a time, verifies each, and halts on the first failure. Outbound-only, so agents behind NAT or Tailscale update themselves.
- Staged rollout with a human-approval gate and per-node halt-on-failure
- SHA-256-verified artifacts, atomic version flip, one-symlink rollback
- Health-gated: a node stays Ready past a soak window before the next
- Fleet-wide version visibility on every
FleetNode - Bounded download size and automatic old-version garbage collection
OpenShift First-Class
v0.7.7Deploy LLMKube on OpenShift, OKD, or MicroShift in one Helm command. The chart's values-openshift.yaml preset disables the operator's default fsGroup so the restricted-v2 SCC can inject its own from the namespace range. No SCC tuning, no oc adm policy dance.
- Ships
charts/llmkube/values-openshift.yamlpreset - Controller flag
--default-fsgroup(0 disables on SCC) - MicroShift-backed e2e CI job guards admission compatibility
- Production-validated for regulated industries (healthcare, defense, finance)
- Works alongside vanilla K8s on the same chart
mlx-server on Apple Silicon
v0.7.9An OpenAI-compatible MLX inference server, managed by the metal-agent as a first-class runtime. Run brew install defilantech/tap/mlx-server, set spec.runtime: mlx-server, and the agent handles the process lifecycle, health probes, and memory pre-flight.
- OpenAI-compatible API with streaming, tool calling, and reasoning split
- 102.7 tok/s single-stream on an M5 Max (Qwen3.6-35B-A3B 8-bit)
- 107 ms time-to-first-token
- Same Prometheus / health-probe surface as the other runtimes
- Installed from the Homebrew tap with binary auto-discovery
vllm-swift on Apple Silicon
v0.7.7Native vLLM on Apple Silicon via TheTom's Swift bridge, as a first-class LLMKube runtime. Set spec.runtime: vllm-swift and the metal-agent handles the rest, with TurboQuant KV cache passthrough on the same CRD shape you use for CUDA.
- vllm-swift binary auto-discovery (
--vllm-swift-binoverride) - TurboQuant quant-scheme + quant-bits passthrough via
kvCacheCustomDtype - Same Prometheus / health-probe surface as the other runtimes
- Sample manifest for Qwen3 4B FP8 + TurboQuant
- Built on the M5 Max long-context benchmarks
Memory-Pressure Protection
Updated v0.7.7Stop the metal-agent from killing your only inference workload when system memory spikes. Priority-based eviction, a friendly-fire guard for legitimate primary consumers, a per-service opt-out, and (new in 0.7.7) Kubernetes events on every pressure transition that kubectl describe picks up.
- Watchdog levels with
MemoryPressurestatus condition - Eviction-safety floor: never evicts the last managed process
evictionProtection: trueperInferenceService- 50% RSS friendly-fire guard against external pressure spikes
- Kubernetes events on pressure / eviction / respawn-blocked transitions
TurboQuant KV Cache
v0.7.3First-class support for fork-specific KV cache types like TurboQuant turbo3, turbo4 on Metal and turbo2 on vLLM. Up to ~6.4× KV cache compression vs f16, which is what unlocks 256K–1M context for agentic coding on a single MacBook.
cacheTypeCustomK/cacheTypeCustomVfor llama.cpp forkskvCacheCustomDtypefor vLLM v0.20+turbo2- Cache-type-aware memory pre-flight check (no false OOM on TurboQuant)
- Spec-drift respawn:
kubectl patch isvcpicks up KV cache changes - Cross-runtime: same CRD shape on Metal and CUDA
Apple Silicon Power Telemetry
v0.7.2Live SoC power gauges (CPU + GPU + ANE) sourced from macOS powermetrics. Pairs with InferCost for end-to-end $/MTok cost attribution on M-series Macs, where DCGM doesn't exist.
- Four Prometheus gauges: combined / GPU / CPU / ANE watts
- Opt-in via
--apple-power-enabledflag - One-command
make install-powermetrics-sudowith pinned-argv NOPASSWD entry - Security audit fixed three findings before merge
- Agrees with InferCost reading within ~1.6 W under sustained load
Hybrid GPU/CPU Offloading
v0.7.0Run 30B+ MoE models on consumer GPUs. Expert weights in system RAM, active path on GPU, scheduler-aware host memory requests.
- moeCPUOffload, moeCPULayers, noKvOffload fields
- hostMemory request for scheduler placement
- Tensor overrides and batch-size controls
- Seven new runtime controls for llama.cpp and vLLM
- HuggingFace repo ID source for runtime-resolved models
Pluggable Runtime Backends
Updated v0.7.9Choose the best inference engine for your workload. One CRD, seven runtimes (including the new mlx-server MLX path for Apple Silicon), and FP8-friendly tuning via gpuMemoryUtilization + cpuOffloadGB on vLLM.
- vLLM with PagedAttention, tensor parallelism, and per-rank CPU offload (community PR)
- vllm-swift for native Apple Silicon with TurboQuant passthrough
- mlx-server for OpenAI-compatible MLX inference on Apple Silicon
- TGI (HuggingFace Text Generation Inference)
- llama.cpp with GGUF and low-memory efficiency
- Generic runtime for custom containers
HPA Autoscaling
v0.6.0Scale inference replicas automatically based on real metrics. Per-runtime metric defaults.
- Kubernetes HPA with custom inference metrics
- Configurable min/max replicas and target values
- Per-runtime default metrics via HPAMetricProvider
- Works with Prometheus Adapter
Inference Metrics Dashboard
Updated v0.7.7Pre-built Grafana dashboard plus shipped Prometheus recording rules for p95 latency and TTFT across runtimes. The new inference.llmkube.dev/runtime pod label is promoted onto every series so group-by-runtime queries are free.
- Recording rules: p95 request latency, p95 TTFT, llama.cpp request latency
- Per-model, per-runtime, per-namespace breakdowns out of the box
- Import-ready JSON in
docs/grafana/llmkube-inference.json - PodMonitor relabelings ship in the Helm chart
GPU Acceleration
Updated v0.6.0NVIDIA CUDA 13 support with Blackwell GPUs. Custom layer splits via GPUShardingSpec.
- CUDA 13 with Blackwell and Qwen3.5 support
- Custom layer splits from GPUShardingSpec
- 64 tok/s on Llama 3.2 3B (17x faster than CPU)
- GKE + NVIDIA GPU Operator ready
Metal Agent
Three pluggable runtime backends for Apple Silicon inference. Choose the best fit for your workflow.
- Ollama backend (200K+ users, auto model download)
- oMLX backend (MLX-native, 40% faster)
- llama-server backend (direct llama.cpp control)
- M1/M2/M3/M4/M5 with health checks and metrics
KV Cache & Advanced Config
Fine-tune llama.cpp and vLLM behavior through the CRD. Standard cache types are enum-validated; fork-specific types pass straight through.
- cacheTypeK / cacheTypeV (llama.cpp standard enum)
- kvCacheDtype (vLLM auto / fp8_e5m2 / fp8_e4m3)
- cacheTypeCustomK/V and kvCacheCustomDtype for fork values
- extraArgs escape hatch for any runtime flag
GPU Queue Visibility
See where workloads stand in the GPU queue. Priority classes control scheduling.
- Real-time queue position in status
- GPU contention visibility
- Priority classes for scheduling control
GPU Monitoring
Prometheus and Grafana integration with DCGM GPU metrics and pre-built dashboards.
- GPU utilization, temp, power monitoring
- Pre-built Grafana dashboards
- Prometheus metrics integration
Kubernetes Native
Updated v0.7.6Custom Resource Definitions for Model and InferenceService. Works with kubectl, GitOps, and the rest of your platform stack.
- Mutable
modelRef: swap models without recreating the service runtimeClassNamefor gVisor, Kata, or custom runtimespodAnnotations+podLabelsfor service mesh and policy- Declarative YAML, GitOps-ready, standard K8s patterns
Automatic Model Management
Download from HuggingFace, HTTP, or PVC sources. Automatic caching and SHA256 validation.
- HuggingFace + HTTP + PVC sources
- GGUF format support
- Persistent volume caching
OpenAI Compatible
Drop-in replacement for OpenAI API. Use existing tools without code changes.
- /v1/chat/completions endpoint
- Streaming responses
- Compatible with LangChain, etc.
CLI Tool
Simple command-line interface for deploying and managing LLM workloads.
- Deploy with --gpu flag
- List, status, delete commands
- macOS, Linux, Windows binaries
CLI Benchmark Suites
Five test suites for comprehensive validation with automated sweeps and markdown reports.
- llmkube benchmark --suite quick
- Concurrency, context, and token sweeps
- Markdown reports for sharing
Grafana Dashboard
Pre-built GPU observability dashboard for monitoring utilization, temperature, and memory.
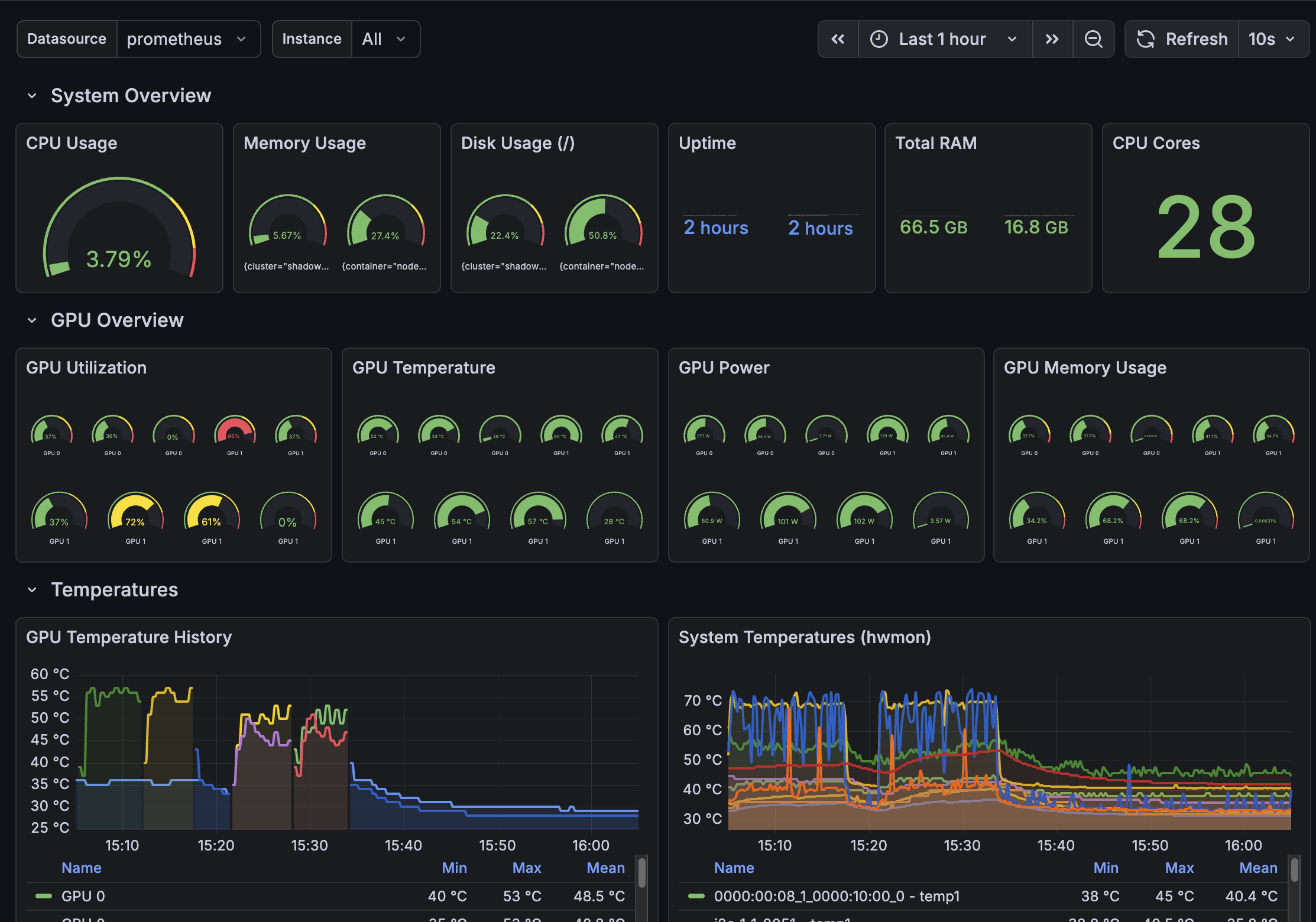
- Multi-GPU monitoring with DCGM
- Import-ready JSON in config/grafana/
Persistent Model Cache
Download models once, deploy instantly across services. Reduce bandwidth and startup times.
- Per-namespace model cache PVC
- Instant model switching
- Configurable cache invalidation
Model Catalog
20+ pre-configured models. Deploy instantly with optimized settings.
- One-command deployments
- Llama, Mistral, Qwen, DeepSeek, Mixtral, Phi
- Smart defaults with override support
Multi-GPU Support
Deploy 13B-70B+ models across GPUs with automatic layer sharding.
- ~44 tok/s on Llama 13B with 2x RTX 5060 Ti
- Automatic tensor split calculation
- Layer-based sharding
Multi-Cloud Support
Deploy on any Kubernetes distribution. Standard K8s patterns.
- Tested on GKE, kind, Minikube
- Works on AKS, EKS, bare metal
- Custom tolerations and nodeSelector
Helm Chart
Production-ready chart with 50+ configurable parameters.
- helm install llmkube llmkube/llmkube
- ImagePullSecrets for private registries
- Namespace isolation, RBAC included
Validated performance
Real benchmarks from GKE deployments — CPU and GPU
CPU Baseline
TinyLlama 1.1B on GKE n2-standard-2- Token generation
- ~18.5 tok/s
- Prompt processing
- ~29 tok/s
- Response time
- ~1.5s (P50)
- Cold start
- ~5s
GPU Accelerated
Llama 3.2 3B on GKE + NVIDIA L4- Token generation
- ~64 tok/s
- Prompt processing
- ~1,026 tok/s
- Response time
- ~0.6s
- GPU memory
- 4.2 GB VRAM
- Power usage
- ~35W
What's coming next
AI gateway integration, SLO contracts, multi-tenancy, and air-gapped sovereignty
First-Class AI Gateway Integration
The operator programs an Envoy AI Gateway from InferenceService and ModelRouter state, so the gateway becomes fleet-aware.
- Routes appear and disappear with InferenceServices
- Cross-tier failover across CUDA pods and Metal hosts under one model name
- Auth, token budgets, and audit declared once in LLMKube CRDs
SLO Contracts and Multi-Tenancy
Per-InferenceService SLOs and tenant isolation for shared GPU fleets.
- Per-InferenceService SLO declaration via Pyrra, with SLO-aware routing
- GPUQuota CRD with an admission webhook and RBAC bundle
- TTFT and per-request error-rate metrics
Multi-Cluster Federation
Datacenter plus multi-site edge fleets under one control plane, with geo-aware placement and routing.
Air-Gapped Model Sources
Local and private model registries for fully disconnected, sovereign deployment.
Multi-Node GPU Sharding
Distribute 70B+ models across multiple GPU nodes with intelligent layer scheduling and P2P KV cache sharing.
Intel GPUs and B200-Class Validation
Configurable GPU resource names for Intel GPU scheduling, plus NVIDIA B200 (sm_100) datacenter-class validation.
We build incrementally with production validation at each step. Roadmap subject to change based on community feedback.
Ready to get started?
Deploy your first GPU-accelerated LLM in minutes.