The Model I Deployed Wrote My Operator's Next Feature

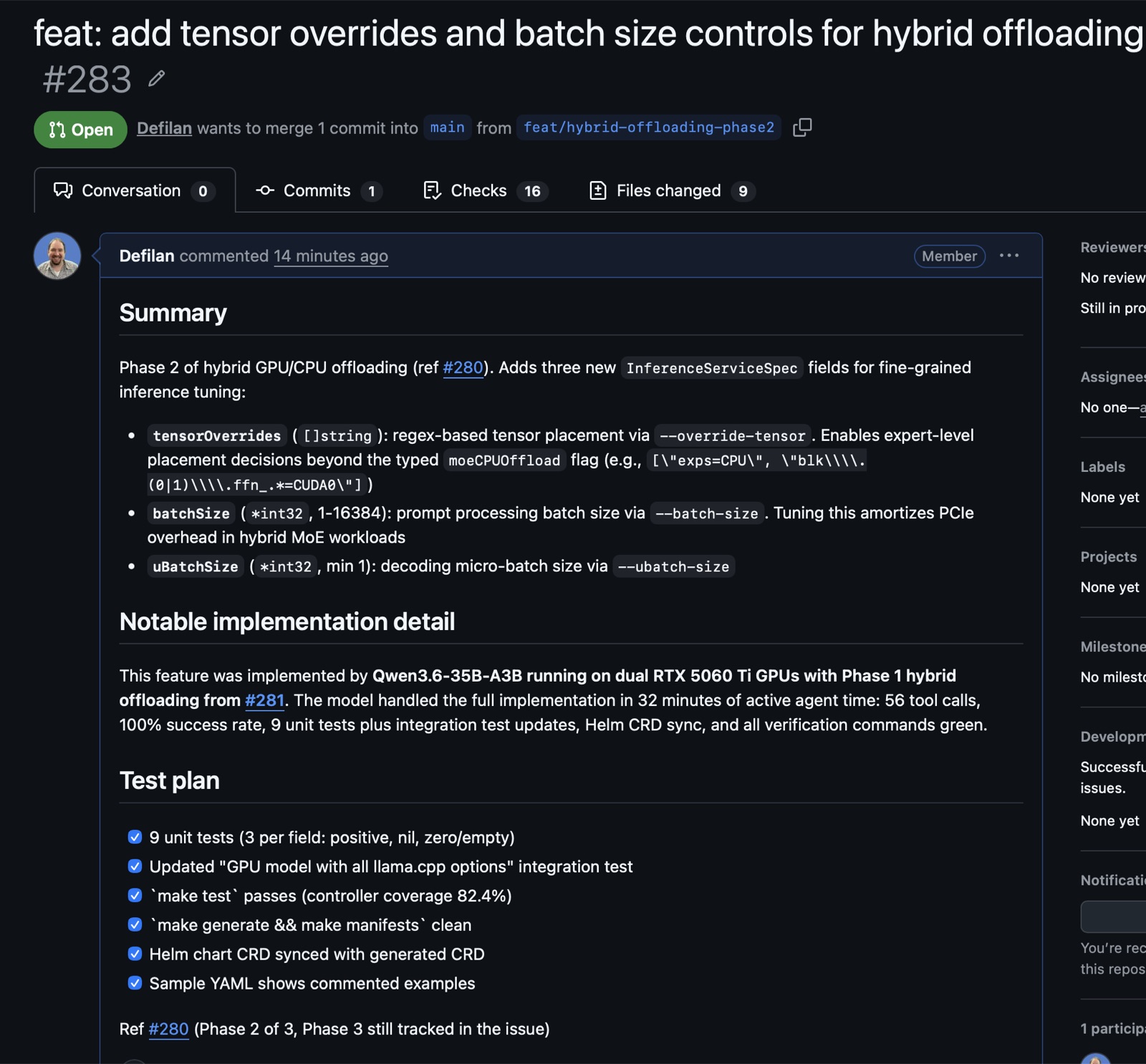
Yesterday I shipped Phase 1 of hybrid GPU/CPU offloading for LLMKube. By this morning the model I deployed with that feature had written Phase 2 for me. 56 tool calls, 100% success rate, every test green. It was merged as PR #283.
The model was Qwen 3.6 35B-A3B, released April 15. It ran on the same two RTX 5060 Ti GPUs that sit in my home office, served by LLMKube, with the Phase 1 offloading support I had just merged. Expert weights in system RAM, active path on GPU, 90K context with a near-lossless KV cache. The operator was deploying the model that was modifying the operator. This post is about what that loop looked like, why it worked, and the benchmarks that made it possible.
The Result
I gave the agent a single prompt pointing at a spec document I had written, and I went to bed. When I checked in the morning, every task on its todo list was complete.
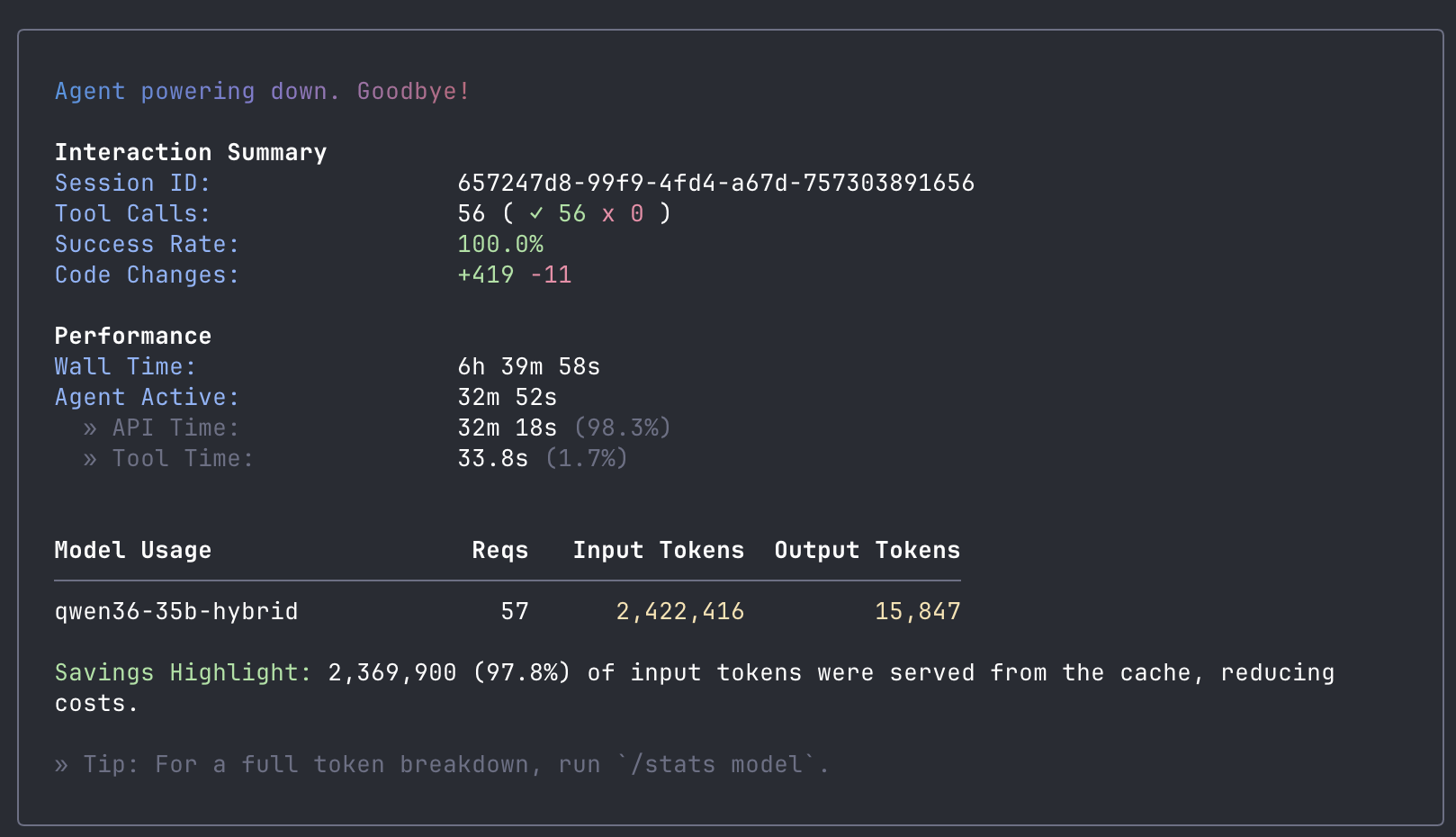
| Metric | Value |
|---|---|
| Wall time | 6 hours 39 minutes |
| Agent active time | 32 minutes 52 seconds |
| Tool calls | 56 (100% success) |
| Code changes | +419 / -11 lines across 6 files |
| Output tokens | 15,847 |
| Prompt cache hit rate | 97.8% |
| Tests added | 9 unit tests + integration test update |
| API cost | $0 |
It added three new CRD fields to InferenceServiceSpec, wrote helper functions following the existing codebase patterns, wired them into the llama.cpp argument builder, wrote tests for every field across positive, nil, and zero cases, updated an existing integration test to cover the new flags, synced the Helm chart CRD with the generated one, and then ran make generate, make manifests, and make test to verify everything. Controller test coverage went from 82.6% to 82.4%, which is within rounding.
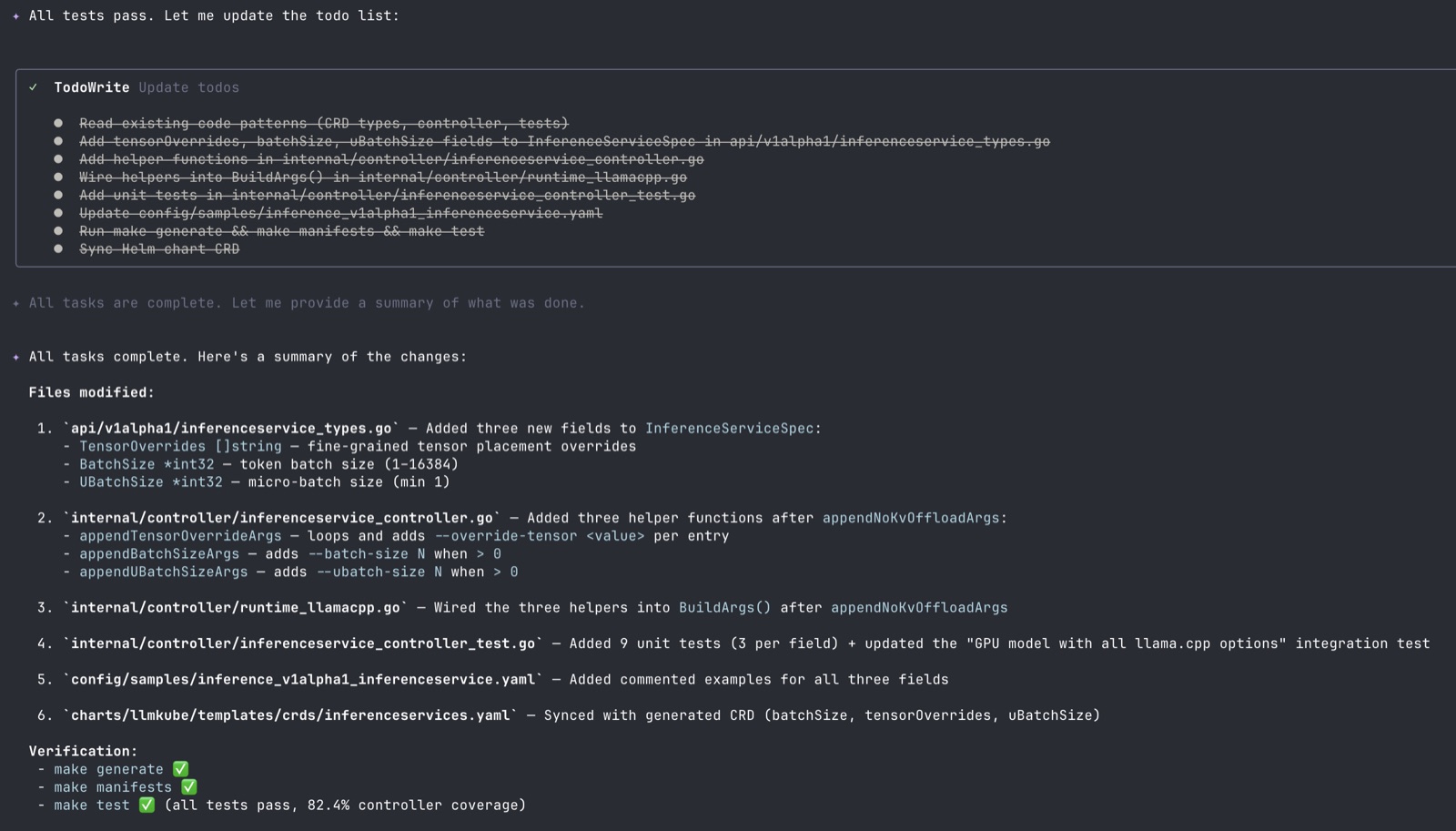
I reviewed the diff as if it were a PR from an external contributor. The only thing I asked it to change was a stale example comment that mentioned --batch-size as an ExtraArgs escape-hatch value, which was misleading now that --batch-size had its own typed field. That was it. The PR was merged.
The Setup
The hardware is the same ShadowStack build from earlier posts: one AMD desktop in my home office, two NVIDIA RTX 5060 Ti GPUs at 16GB of VRAM each, 64GB of system RAM, running MicroK8s. Combined GPU cost is about $900. The combined memory bandwidth is much lower than an H100. What makes it work is the software stack.
Hybrid GPU/CPU offloading is a specific trick for Mixture of Experts (MoE) models. A 35B-A3B model has 35 billion total parameters but only about 3 billion active per token. The rest of the experts sit idle for that token. If you keep all of them in VRAM you are paying for storage that is mostly unused. If you push the inactive experts to system RAM and keep only the active path on GPU, you can run much larger models than your VRAM budget would normally allow.
Phase 1 of that feature (merged as PR #281) added four CRD fields: moeCPUOffload, moeCPULayers, noKvOffload, and hostMemory. The first three map to llama.cpp flags that push MoE expert weights and the KV cache to system RAM. hostMemory makes Kubernetes aware that the pod needs real system RAM for offloading, so the scheduler places it on a node that can sustain the working set.
apiVersion: inference.llmkube.dev/v1alpha1
kind: InferenceService
metadata:
name: qwen36-hybrid
spec:
modelRef: qwen36-35b-hybrid
contextSize: 90112
cacheTypeK: q8_0
cacheTypeV: q8_0
moeCPUOffload: true # expert weights to CPU RAM
noKvOffload: true # KV cache to CPU RAM
flashAttention: true
jinja: true
resources:
gpu: 2
cpu: "8"
hostMemory: "48Gi" # system RAM request for offloadingDeploying Qwen 3.6 this way fits comfortably on dual 16GB cards. The active path sits on GPU, the routed expert weights live in system RAM, and the KV cache at 90K context occupies roughly 20GB of RAM instead of VRAM. The pod starts up in under a minute once the model is cached. Generation runs at 21.7 tokens per second.
Why Hybrid Offloading Matters
Before swapping in Qwen 3.6 I ran the same benchmark harness across three models on the same dual 5060 Ti hardware. Sequential generation, 10 iterations, 128 max tokens per request, with 2 warmup requests to prime the KV cache. Then a stress test at 4 concurrent workers for 5 minutes at 256 tokens per request.
The models were deliberately chosen to show the tradeoff space. Qwen 3.5-27B is a dense model, fully on GPU with layer sharding, running through a custom llama.cpp build with TurboQuant KV cache quantization. Qwen 3 Coder-30B-A3B is the purpose-built coding MoE, running with the new hybrid offloading. Qwen 3.6-35B-A3B is the general MoE that replaced it, also using hybrid offloading, with stronger agentic benchmarks.
| Model / Config | Generation (single) | P50 latency | Stress (4 concurrent) |
|---|---|---|---|
| Qwen 3.5-27B dense (full GPU) | 18.3 tok/s | 7,196 ms | 10.4 tok/s, 52 req / 5min |
| Qwen 3 Coder-30B-A3B (hybrid) | 31.1 tok/s | 2,286 ms | 12.0 tok/s, 113 req / 5min |
| Qwen 3.6-35B-A3B (hybrid) | 21.7 tok/s | 6,160 ms | 6.8 tok/s, 38 req / 5min |
The single-request jump from Qwen 3.5 dense to Qwen 3 Coder hybrid is the hybrid offloading story in one line: 70% faster generation, P50 latency cut to a third, on the same GPUs. Moving from reading 18.3GB per token to reading the 3B active path gives you most of the speedup, even with expert weights in system RAM and the KV cache crossing PCIe for every layer.
Qwen 3.6 is slower than the Coder variant because the total parameter count is 5B higher, which means more expert weight traffic through system memory. But 21.7 tok/s on a 35B model with a larger quality ceiling than either alternative is the interesting number here. Qwen 3.6 scores 73.4% on SWE-bench Verified and 51.5% on Terminal-Bench 2.0 per its release benchmarks. That is the strongest open-weight model you can fit in 32GB of combined VRAM right now, and the hybrid offloading is what makes fitting it possible.
Why the dense model has faster prompt processing:
The dense Qwen 3.5-27B processes prompts at 160 tok/s because all 27B parameters live on GPU and never cross PCIe. The MoE hybrid models process prompts at 30-95 tok/s because the expert weights need to be touched in system RAM during the prompt phase. For agentic coding the generation speed matters far more than prompt speed, and the dense model cannot catch up on generation without sacrificing context window. The choice is really which bottleneck you want to pay for.
How It Went
The prompt was simple. I had written a spec document at docs/hybrid-offload-phase2-spec.md that described the three fields to add (tensorOverrides, batchSize, uBatchSize), the files that needed to change, and the existing Phase 1 patterns to follow. The prompt to Qwen Code was: "Read docs/hybrid-offload-phase2-spec.md and implement everything it describes. Follow the existing patterns in the codebase exactly. When done, run make generate and make manifests and make test to verify everything passes."
It started by writing itself a todo list of 8 items. Then it read the spec, cross-referenced the Phase 1 patterns by pulling up inferenceservice_types.go and the existing arg helper functions, and got to work. It added the three new fields in the right place in the struct. It wrote three new helper functions with the right nil-and-zero guards. It wired them into BuildArgs() in the correct spot (after the Phase 1 helpers, before the ExtraArgs escape hatch).
Then it wrote nine unit tests covering every positive, nil, and zero case, following the exact structure of the Phase 1 tests. It updated the "GPU model with all llama.cpp options" integration test to include the new fields. It updated the sample YAML with commented examples. It ran make generate, noticed the deepcopy was regenerated, ran make manifests, saw the CRD schema updated, and then manually synced the Helm chart CRD with the generated one because that file lives outside the kustomize tree and is not auto-regenerated. This is the kind of out-of-band detail that I had specified in the spec document, but it could have easily been missed or handled incorrectly.
The output is worth reading as a PR. Every Go function matches the naming and style of its Phase 1 counterpart. Every test uses the same fixture pattern. The CRD schema is in alphabetical order because that is how controller-gen emits it. The Helm chart CRD matches the generated one. No dead code, no scaffolding left behind.
Two things stand out in the session stats. First, the cache hit rate was 97.8%. The model read the repo once to build context, then did 55 more requests against that cache. That is the pattern llama.cpp is optimized for, and it is why the effective throughput for agentic work is much higher than the raw generation speed suggests. Second, only 1.7% of the active time was tool execution. The rest was generating tokens. The shape of the work is overwhelmingly "think about the next thing to write."
The TurboQuant Detour
Before swapping in Qwen 3.6 I tried an optimization. Our custom llama.cpp image with TurboQuant KV cache quantization has been serving the dense Qwen 3.5-27B at 128K context on the same hardware for weeks. The TurboQuant cache formats (tbqp3, tbq3) compress the KV cache three to four times more aggressively than q8_0. Combining hybrid offloading with TurboQuant should have been the best of both worlds: experts in system RAM plus a much smaller KV cache, which would let me push context from 90K to 131K while reducing the hostMemory request from 48Gi to about 24Gi.
The pod crashed. Exit code 139, segfault during warmup. I isolated the variables. The crash happened with --cpu-moe. It also happened without --cpu-moe at 131K context. The logs pointed at "fused Gated Delta Net" kernels, which are a TurboQuant optimization for the hybrid attention layers in the Qwen 3 MoE architecture. Something in that code path does not survive the memory layout our MoE model needs. The TurboQuant fork we run is compatible with the dense Qwen 3.5-27B, but not yet compatible with Qwen 3 and Qwen 3.6 MoE variants.
So I dropped back to the stock ghcr.io/ggml-org/llama.cpp:server-cuda13 image with q8_0 KV cache at 90K context. The benchmarks in this post were run against that configuration. Once the TurboQuant fork adds MoE Gated DeltaNet support, that combination will be worth revisiting. For now, stock llama.cpp with hybrid offloading is the proven path. I also filed issue #282 to add custom cache type strings to the CRD so users do not have to use extraArgs as a workaround for non-standard cache formats.
The Honest Assessment
I want to be specific about what this does and does not mean.
- The task had a spec document. The agent did not invent the shape of Phase 2 from scratch. I wrote a markdown file that described the fields to add, the files to change, and the existing patterns to follow. It was roughly the briefing you would give an engineer who had not seen the codebase before. What the model did was read and execute that spec faithfully, and it did it well. But the design choices were mine.
- The work was well scoped. Phase 2 is three new fields in an established pattern from Phase 1 of the same feature. The model had a clear template to copy. I would not trust this setup to do a design-level task that required original architectural thinking.
- Active time is not wall time. 32 minutes of active generation stretched across nearly 7 hours of wall time because my laptop went to sleep and the agent waited. At 21.7 tokens per second you feel the pace. This is not interactive coding. It is the overnight pattern from the previous post, validated on a harder task.
- One non-trivial review catch. The PR review agent flagged a stale comment in the
ExtraArgsdocumentation that referenced--batch-sizeas an example. Since Phase 2 made--batch-sizea typed field, the example was now misleading. The model would not have caught this on its own. A human reviewer did.
What it did do, unambiguously, is take a spec and ship a merge-ready PR. Every verification command passed. Every test file was structured like the existing tests. Every pattern matched. If this PR had come in from a GitHub contributor I had never met, I would have merged it the same afternoon.
What This Means
The recursion is the point. An operator I am building to run local inference on consumer hardware was deploying the model that shipped the operator's next feature. The whole loop happened on my desk, on hardware that cost less than a monthly cloud GPU bill, with nothing leaving the network.
The practical shift is that well-scoped implementation work is moving to a place where it costs only electricity. If I can describe a feature in a spec document clearly enough that an agent can read it and implement it, the work happens for the price of running two GPUs for 32 minutes. The leverage point moves up. What matters is the spec, the review, the decision about what to build. The typing of it is increasingly free, overnight, at home.
And the trend line for local model quality keeps getting steeper. Qwen 3.5-27B landed in early 2026 with 72.4% on SWE-bench Verified. Qwen 3.6 arrived two months later at 73.4%, with sharp gains on Terminal-Bench (+11 points) and MCPMark (+10 points), which measure the exact kind of multi-step agentic coding we are doing. Hybrid offloading is how you run those gains on hardware you can fit under your desk. The Kubernetes operator is how you make it reproducible enough to trust with overnight work.
Try It Yourself
If you have two GPUs with 16GB each and a box with 64GB of RAM, you can run this setup. The Qwen 3.6 GGUF is on HuggingFace, and the hybrid offloading fields shipped in LLMKube 0.7.0.
1. Deploy LLMKube (0.7.0+ required for hybrid offloading)
helm repo add llmkube https://defilantech.github.io/LLMKube
helm install llmkube llmkube/llmkube \
--namespace llmkube-system \
--create-namespace2. Deploy the model and hybrid inference service
apiVersion: inference.llmkube.dev/v1alpha1
kind: Model
metadata:
name: qwen36-35b-hybrid
spec:
source: https://huggingface.co/bartowski/Qwen_Qwen3.6-35B-A3B-GGUF/resolve/main/Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf
format: gguf
quantization: Q4_K_M
hardware:
accelerator: cuda
gpu:
enabled: true
count: 2
vendor: nvidia
resources:
cpu: "8"
memory: "16Gi"
---
apiVersion: inference.llmkube.dev/v1alpha1
kind: InferenceService
metadata:
name: qwen36-hybrid
spec:
modelRef: qwen36-35b-hybrid
replicas: 1
image: ghcr.io/ggml-org/llama.cpp:server-cuda13
contextSize: 90112
cacheTypeK: q8_0
cacheTypeV: q8_0
moeCPUOffload: true
noKvOffload: true
flashAttention: true
jinja: true
resources:
gpu: 2
cpu: "8"
hostMemory: "48Gi"3. Point Qwen Code at the local endpoint
kubectl port-forward svc/qwen36-hybrid 8080:8080 &
# ~/.qwen/settings.json
{
"modelProviders": {
"openai": [{
"id": "qwen36-35b-hybrid",
"name": "Qwen3.6-35B Hybrid (LLMKube)",
"baseUrl": "http://localhost:8080/v1",
"envKey": "OPENAI_API_KEY"
}]
},
"model": { "name": "qwen36-35b-hybrid" }
}
export OPENAI_API_KEY=sk-local
qwenFrom there, give it a spec document and a clear prompt. Then go do something else for a while. The model LLMKube deploys can now ship LLMKube features. That is an unusually literal form of dogfooding, and it works.
Update (April 18, 2026)
The --cpu-moe flag in the config above is unnecessary for Qwen 3.6 on dual 16 GB cards. The flag trades VRAM savings for CPU compute cost: every token pays for the CPU to run the expert matmuls rather than the GPU. That trade only pays off when the model-plus-context combination actually overflows VRAM. Qwen 3.6's hybrid DeltaNet architecture keeps the KV cache small (only 10 of 40 layers contribute to it), so at Q4_K_M and 90K context the model fits in 32 GB of VRAM without any offloading — meaning the CPU cost is pure overhead.
Removing the flag on the same pod takes generation from 21.7 tok/s to 107.8 tok/s. Same GPUs, same GGUF, same context window. The full mechanism walkthrough (including why the same flag correctly ran Qwen3-Coder-30B at 31 tok/s on this hardware) is in Why Qwen 3.6 Doesn't Need --cpu-moe (and Why Qwen3-Coder Does) on Dual 16GB.
Investigating the interaction also surfaced a set of adjacent gaps in LLMKube's runtime coverage. PR #291 bundles seven new runtime controls into LLMKube 0.7.0, including a sharding-strategy behavior correction, vLLM extraArgs passthrough, prefix caching, attention backend selection, reasoning budget caps, and GGUF metadata overrides.
Resources: The LLMKube repository has the operator, sample manifests, and Helm chart. PR #281 added Phase 1 of hybrid offloading. PR #283 added Phase 2, written by the model. Issue #280 tracks the full roadmap including Phase 3.
Run Your Own Agentic Coding Setup
LLMKube manages model downloads, GPU scheduling, hybrid offloading, and exposes an OpenAI-compatible API. Point any agentic tool at it and keep every token on your network.